概述
背景
扩展机制和扩展点作为Dubbo设计的核心机制,不仅是Dubbo能够适应不同公司的技术需要,流行至今的重要引出,也是Dubbo本身生态不断完善,功能越来越强大的核心原因之一
扩展点整体架构
按使用者和开发者来分,Dubbo可以分为API层和SPI层.API层让用户只关注业务的配置,直接使用框架API即可;SPI层可以让用户自定义不同的实现类来扩展整个框架的功能
按逻辑来区分,可以把Dubbo从上到下分为三层:业务层,RPC层,Remote层
RPC层扩展点
RPC层分为四层:Config,Proxy,Registry,Cluster
Proxy层扩展点
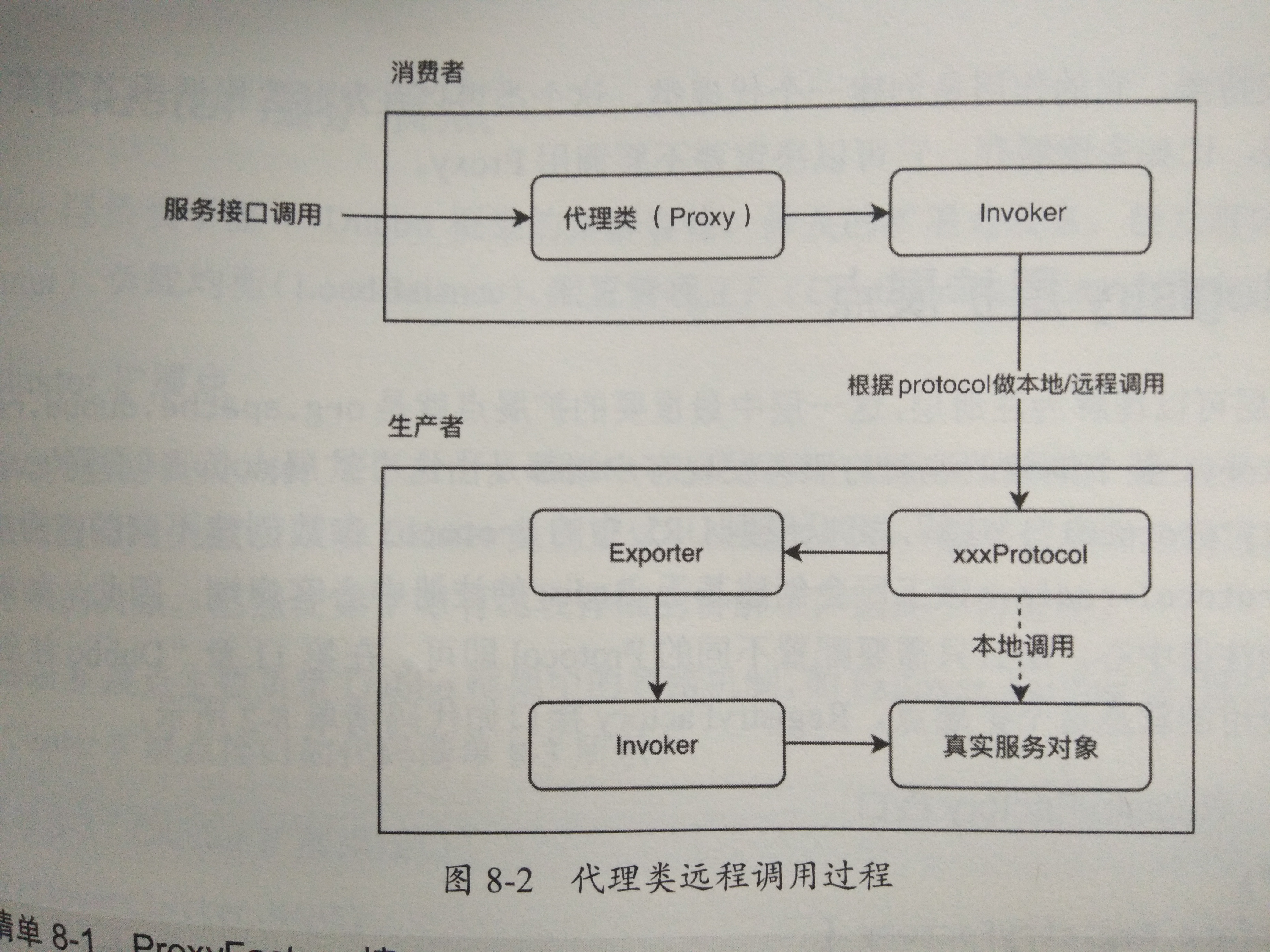
Proxy层主要的扩展接口是ProxyFactory.ProxyFactory帮我们生成了代理类,当我们请求某个远程接口时,实际上使用的是代理类
Dubbo中的ProxyFactory有两种默认实现,Javassist和JDK,用户可以自行扩展自己的实现,如CGLib.基于性能和使用的建议性考虑,Dubbo选用Javassist作为默认的字节码生成工具
1 |
|
Registry层扩展
这一层最重要的扩展是org.apache.dubbo.registry.RegistryFactory.整个框架的注册与服务发现客户端都是这个扩展点负责创建的.该扩展点有@Adaptive({“protocol”})注解,可以根据URL中的protocol参数创建不同的注册中心客户端.如果我们扩展了自定义的注册中心,那么只需要配置不同的protocol即可.
1 |
|
使用这个扩展点,还有一些需要遵循的规则:
- 如果URL中设置了check=false,则连接不会被检查.否则,需要在断开连接时抛出异常
- 需要支持通过username:password格式在URL中传递鉴权
- 需要支持设置back参数来执行备选注册集群的地址
- 需要支持file参数来指定本地文件缓存
- 需要设置timeout参数来指定请求的超时时间
- 需要支持设置session参数来指定连接的超时或过期时间
Cluster层扩展点
Cluster层负责了整个Dubbo框架的集群容错,设计的扩展点较多,包括容错(Cluster),路由(Router),负载均衡(LoadBalance),配置管理工厂(ConfiguratorFactory)和合并器(Merger)
Cluster扩展点
Cluster主要负责一些容错策略,也是整个集群容错的入口.当远程调用失败后,由Cluster负责重试,快速失败等,整个过程对上层透明
Cluster扩展点默认使用Failover机制
1 |
|
Cluster接口只有一个join方法,并且有@Adaptive注解,会根据配置动态调用不同的容错机制
RouteFactory扩展点
RouterFactoryFactory是一个工厂类,用于创建不同的Router.假设接口A有多个服务提供者提供服务,如果配置了路由规则(某个消费者只调用某几个提供者),则Router会过滤掉其他服务提供者,只留下符合路由规则的提供者列表
1 |
|
现有的路由规则支持文件,脚本和自定义表达式等方式.接口上有@Adaptive(“protocol”)注解,会根据不同的protocol自动匹配路由规则
| 扩展key名 | 扩展类名 |
|---|---|
| file | org.apache.dubbo.rpc.cluster.router.file.FileRouterFactory |
| script | org.apache.dubbo.rpc.cluster.router.script.ScriptRouterFactory |
| condition | org.apache.dubbo.rpc.cluster.router.condition.ConditionRouterFactory |
| server | org.apache.dubbo.rpc.cluster.router.condition.config.ServiceRouterFactory |
| app | org.apache.dubbo.rpc.cluster.router.condition.config.AppRouterFactory |
| tag | org.apache.dubbo.rpc.cluster.router.tag.TagRouterFactory |
| mock | org.apache.dubbo.rpc.cluster.router.mock.MockRouterFactory |
LoadBalance扩展点
Dubbo的LoadBalance默认使用随机算法
1 |
|
ConfiguratorFactory
创建配置实例的工厂类,现有override和absent两种工厂实现,分别会创建OverrideConfigurator和AbsentConfigurator两种配置对象
OverrideConfigurator会直接把配置中心中的参数覆盖本地参数
AbsentConfigurator会先看本地存在该 配置,有则不会覆盖
1 |
|
Merge扩展点
合并器,可以对并行调用的结果进行合并.例如:并行调用A,B两个服务器都会返回一个List结果集,Merge可以把两个List合并成一个返回给应用.用户可以基于该扩展点,添加自定义类型的合并器
1 |
|
默认已支持:map, set, list, byte, char, short, int, long, float, double, boolean
Remote层扩展点
Remote处于整个Dubbo框架的底层,设计协议,数据的交换,网络的传输,序列化,线程池等,覆盖了一个远程调用的所有要用
Remote层是对Dubbo传输协议的封装,内部再划分为Transport传输层和Exchange信息交换层.其中Transport层只负责单项消息传输,是对Mina,Netty等传输工具库的抽象.而Exchange层在传输层智商实现了Request-Response语义,这样我们可以在不同传输方式智商都能做到统一的请求/响应处理.Serialize层是RPC的一部分,决定了在消费者和服务提供者之间的二进制数据传输格式
Protocol层扩展点
Protocol扩展点
Protocol是Dubbo RPC的核心调用层,具体的RPC协议都可以由Protocol点扩展.如果想新添加一种RPC协议,只需要扩展一个新的Protocol扩展点实现即可.Protocol扩展点接口代码:
1 |
|
Protocol的每个接口会有一些规则,在实现自定义协议的时候需要注意
export方法
- 协议收到请求后应记录请求源IP地址.通过RpcContext.getContext().setRemoteAddress()方法存入RPC上下文
- expoet方法必须实现幂等,即无论调用多少次,返回的URL都是相同的
- Invoker实例由框架传入,无须关心协议层
refer方法
- 当我们调用refer()方法返回Invoker对象的invoker()方法时,协议需要相应地执行invoker方法.这一点在设计自定义协议的Invoker时需要注意
- 正常来说refer()方法返回的自定义Invoker需要继承Invoker接口
- 当URL参数有check=false时,自定义的协议实现必须不能抛出异常,而是在出现连接失败异常时尝试恢复连接
destroy方法
- 调用destroy方法的时候,需要销毁所有本协议暴露和引用的方法
- 需要释放所有占用的资源,如连接,端口等
- 自定义的协议可以在被销毁后继续导出和引用新服务
整个Protocol的逻辑由Protocol,Exporter,Invoker三个接口串起来
Protocol接口是入口,其实现封装了用来处理Exporter和Invoker的方法:
Exporter代表要暴露的远程服务引用,Protocol#export方法是将服务暴露的处理过程,Invoker代表要调用的远程服务代理对象.Protocol#refer方法通过服务类型和URL获得要调用的服务代理
由于Protocol可以实现Invoker和Exporter对象的创建,因此除了作为远程调用对象的构造,还能用于其他用途,如:在创建Invoker的时候对原对象进行包装增强,添加其他Filter进去,ProtocolFilterWrapper实现就是把Filter链加入Invoker.
Filter扩展点
Filter是Dubbo的过滤器扩展点,可以自定义过滤器,在Invoker调用前后执行自定义的逻辑.在Filter的实现中,必须要调用传入的Invoker的invoke方法,否则整个链路就断了
1 |
|
一个invoke函数的实现:
1 | doSomeThingBefore(); |
ExporterListener/InvokerListener扩展点
ExporterListener和InvokerListener这两个扩展点非常相似,ExporterListener是在暴露和取消暴露服务时提供回调;InvokerListener则是在服务引用和销毁引用时提供回调.
ExporterListener扩展点源码:
1 |
|
InvokerListener扩展点源码:
1 |
|
Exchange层扩展点
Exchange层只有一个扩展点接口Exchanger,这个接口主要为了封装请求/响应模式,例如:把同步请求转化为异步请求.默认的扩展点实现是org.apache.dubbo.remoting.exchange.support.header.headerExchanger.每个方法上都有@Adaptive注解,会根据URL中的Exchanger参数决定实现.
1 |
|
Exchange层存在的意义是让上层业务不关注Netty这样的底层Channel.上层一个Request只关注对应的Response,对于是同步还是异步,或者是用什么传输根本不关心.Transport层无法满足这项需求的,Exchange层实现了Request-Response模型,可以理解为对Transport层做了高级封装.
Transport层扩展点
Transport层为了屏蔽不同通信框架的差异,封装了统一的对外接口.主要的扩展点接口有Transport,Dispatcher,Codec2和ChannelHandler
其中ChannelHandler主要处理连接相关的事件,例如:连接上,断开,发送消息,收到消息,出现异常等.虽然接口上有SPI注解,但是在框架中实现类的确实直接new出来的
Transporter扩展接口
Transporter屏蔽了通信框架接口和实现的不同,使用统一的通信接口
1 |
|
bind方法会生成一个服务,监听来自客户端的请求;connect方法则会连接到一个服务.两个方法上都有@Adaptive注解,首先会根据URL中的server的参数值去匹配实现类,如果匹配不到则根据transporter参数去匹配实现类.默认的实现是netty4
Dispatcher扩展接口
如果有些逻辑处理比较慢,如IO等.Dispatcher扩展接口通过不同的派发则略,把工作派发到不同的线程池,以此来应对不同的业务场景
1 |
|
Codec2扩展接口
Codec2主要实现对数据的编码和解码,但这个接口只是需要实现编码/解码过程中的通用逻辑流程,如解决半包,粘包等问题.该接口再序列化上封装了一层.Code2扩展接口:
// TODO: 半包和粘包
// TODO: 第六章还没读
1 |
|
ThreadPool扩展接口
我们在Transport层由Dispatcher实现不同的派发策略,最终会派发到不同的ThreadPool中执行.ThreadPool接口扩展接口就是线程池扩展
1 |
|
框架中默认含有四种线程池扩展的实现:
- fixed
固定大小线程池,启动时简历线程,不关闭,一直持有 - cached
缓存线程池,空闲一分钟自动删除,需要时重建 - limited
可伸缩线程池,但线程池中的线程数只会增长不会收缩,只增长不收缩的目的是为了避免收缩时突然来了大流量引起的性能问题 - eager
优先创建Worker线程池,在任务数量大于corePoolSize小于maximumPoolSize时,优先创建Worker来处理任务,当任务数量大于maximunPoolSize时,将任务放入阻塞队列.阻塞队列充满时抛出RejectedExecutionException(cached在任务数量超过miximumPoolSize时直接抛出异常而不是将任务放入阻塞队列)
Serialize层扩展点
Serialize层主要实现具体的对象序列化,只有Serialization一个扩展接口
1 |
|
其他扩展点
TelnetHandler扩展点
Dubbo支持Telnet命令链接,Telnet接口就是用于扩展新的Telnet命令的接口
TODO:以后再看
StatusChecker扩展点
通过这个扩展点,可以让Dubbo框架支持各种状态的检查,默认已经实现了内存和load的检查.用户可以自定义扩展,如硬盘,CPU等的状态检查
Container扩展点
服务容器就是为了不需要使用外部的Tomcat,JBoss等Web容器来运行服务,因为有可能服务根本用不到它们的功能,只是需要简单地在Main方法中暴露一个服务即可.此时就可以使用服务容器.Dubbo中默认使用SPring作为服务容器
CacheFactory扩展点
我们可以通过dubbo:method配置每个方法的调用返回值是否进行缓存
Validation扩展点
该扩展点主要实现参数的校验,我们可以在配置中使用<dubbo:service validation=“校验实现名” />实现参数校验
LoggerAdapter扩展点
日志适配器用于适配各种不同的日志框架,使其拥有统一的使用接口.
Compiler扩展点
@Adaptive注解会生成Java代码,然后使用编译器动态编译出新的Class.Compiler接口就是可扩展的编译器