Cluster层概述
Cluster的总体工作流程可以分为以下几种:
- 生成Invoker对象
不同的Cluster实现会生成不同类型的ClusterInvoker对象并返回.然后调用ClusterInvoker的Invoker方法,正式开始调用流程 - 获得可调用的服务列表
首先会做前置校验,检查远程服务是否已被销毁.然后通过Directory#list方法获取所有可用的服务列表.接着使用Router接口处理该服务列表,根据路由规则过滤一部分服务,最终返回剩余的服务列表 - 负载均衡
服务列表还需要通过不同的负载均衡策略选出一个服务,首先框架会根据用户的配置,调用ExtensionLoader获取不同负载均衡策略的扩展点实现.然后做一些后置操作,如果是异步调用则设置调用编号.接着调用子类实现的doInvoke方法,子类会根据具体的负载均衡策略选择一个可以调用的服务 - RPC调用
首先保存每次调用的Invoker到RPC上下文,并做RPC调用.然后处理调用结果,对于调用出现异常,成功,失败等情况,每种容错策略会有不同的处理方式.
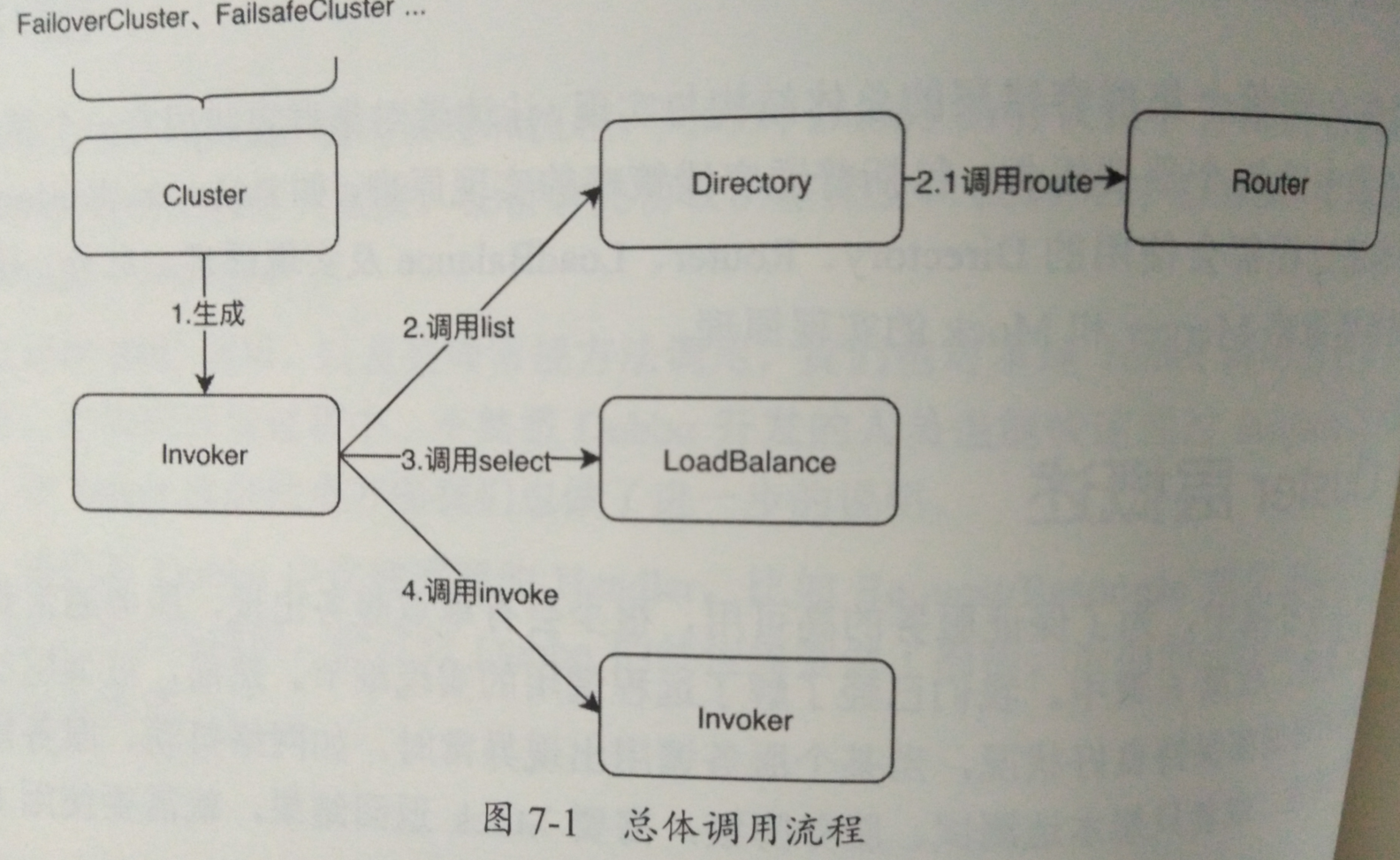
上图是一个全量的通用流程,其中1~3步都是在抽象方法AbstractClusterInvoker中实现的,可以理解为通用的模板流程,主要做了校验,参数准备等工作.
容错机制
Dubbo容错机制能增强整个应用的稳定性,容错过程对上层用户是完全透明的,但用户也可以通过不同的配置项来选择不同的容错机制.每种容错机制又有自己的个性化配置项.
Dubbo各种容错机制的特性:
| 机制名 | 机制简介 |
|---|---|
| Failover | Dubbo默认的容错机制.当出现失败时,会重试其他服务器.可以通过retries=2设置重试次数.会对请求做负载均衡.通常使用在读操作或幂等的写操作上,但重试会导致接口的延迟增大,在下游机器负载已经达到极限时,重试容易加重下游的服务的负载 |
| Failfast | 快速失败,当请求失败后,快速返回异常结果,不做任何重试.该容错机制会对请求做负载聚恒,通常使用在非幂等的接口上.该机制收网络抖动的影响较大 |
| Failsafe | 当出现异常时,直接忽略异常.会对请求做负载均衡.通常使用在"佛系"调用场景,即不关心成功不成功,并不想抛出异常影响外层调用.如某些不重要的异常同步,即使出现异常也无所谓 |
| Failback | 请求失败后,会自动记录在失败队列中,并由一个定时线程池定时重试,适用于一些异步或者最终一致性的请求.会对请求做负载均衡 |
| Forking | 同时调用多个相同的服务,只要其中一个返回,则立刻返回结果.用户可以配置forks="最大并行调用数"参数来确定最大并行调用的服务数量.通常使用在对接口实时性要求极高的调用上,但也会很浪费资源 |