加载机制概述
Dubbo良好的扩展性与两个方面密不可分:一个是整个框架中针对不同场景,恰到好处地使用了各种设计模式,二就是加载机制.基于Dubbo SPI加载机制,让整个框架的接口和具体的实现完全解耦,从而奠定了整个框架良好可扩展性的基础.
Dubbo定义了良好的框架结构,它默认提供了很多可以直接使用的扩展点.Dubbo几乎所有的功能组件都是基于扩展机制(SPI)实现的.
Dubbo没有直接使用Java SPI,而是在它的思想上又做了一定的改进,形成一套自己的配置规范与特性.同时,Dubbo又兼容Java SPI.服务在启动的时候Dubbo就会查找这些扩展点的所有实现.
Java SPI
SPI全称是Service Provider Interface,起初是提供厂商做插件开发的.
Java SPI使用了策略模式,一个接口多种实现.我们只声明接口,具体的实现并不在程序中直接确定,而是由程序之外的配置掌控
1 | +--java |
1 | public interface PrintService{ |
扩展点加载机制的改进
与Java SPI相比,Dubbo SPI做了一定的改进与优化,官方文档有这么一段:
- JDK标准的SPI会一次实例化扩展点所有实现,如果有扩展实现则初始化很好使,如果没有用上也加在,则浪费资源
- 如果扩展加载失败,则连扩展的名称都获取不到了
- 增加了对扩展IoC和AOP的支持,一个扩展可以直接setter注入其他扩展.java.util.ServiceLoader会一次把接口下的所有实现类全部初始化,用户直接调用即可.Dubbo SPI只是加载配置文件中的类,并分成不同的种类缓存在内存中,而不会立即全部初始化,在性能上有更好的表现
1 |
|
Java SPI加载失败,可能会因为各种原因导致异常信息被"吞掉",导致开发人员问题追踪比较困难.Dubbo SPI在扩展加载失败的时候会先抛出真实立场并打印日志.扩展点在被动加载的时候,即使有部分扩展加载失败也不会影响其他扩展点和整个框架的使用.
Dubbo SPI自己实现了IoC和AOP机制,一个扩展点可以通过setter方法直接注入其他扩展的方法,T injectExtension(T instance)方法实现了这个功能.另外,Dubbo支持包装扩展类,推荐把通用的抽象逻辑放到包装类中,用于实现扩展点的AOP特性.比如ProtocolFilterWapper包装扩展了DobboProtocol类,一些通用的判断逻辑全部放在了ProtocolFilterWrapper类的export方法中,但最终会调用DubboProtocol#export方法.这和Spring动态代理思想一样,在被代理的前后插入自己的逻辑进行增强,最终调用被代理类.下面是ProtocolFilterWrapper.export方法:
1 | public <T> Exporter<T> export(Invoker<T> invoker) throws RpcException { |
扩展点的配置规范
Dubbo和Java SPI类似,需要在META-INF/dubbo/下设置对应的SPI配置文件,文件名称需要命名为接口的全路径名.配置文件的内容为key=扩展点实现类全路径名(如: cat=com.ggemo.test.service.Animal),如果有多个实现类则使用换行符分隔.其中,key会作为Dubbo SPI注解中的传入参数.另外,Dubbo SPI还兼容了Java SPI的配置路径和内容配置方式.在Dubbo启动的时候,会默认扫这三个目录下的配置文件:META-INF/services/ ,META-INF/dubbo/ ,META-INF/dubbo/internal/
| 规范名 | 规范说明 |
|---|---|
| SPI配置文件路径 | META-INF/services/ ,META-INF/dubbo/ ,META-INF/dubbo/internal/ |
| SPI配置文件名称 | 全路径类名 |
| 文件内容格式 | key=value方式,多个用换行符分隔 |
扩展点的分类与缓存
Dubbo SPI可以分为Class缓存,实例缓存.这两种缓存有能根据扩展类的种类分为普通扩展,包装扩展类,自适应扩展类等.
- Class缓存
Dubbo SPI获取扩展类时,会先从缓存中读取.如果缓存中不存在,则加载配置文件,根据配置把Class缓存到内存中,并不会直接全部初始化. - 实例缓存
基于性能考虑,Dubbo框架中不仅缓存Class,也会缓存Class实例化后的对象.每次获取的时候,会先从缓存中获取,如果缓存中读不到,则重新加载并缓存起来.
缓存也是为什么Dubbo SPI相对于Java SPI性能上有优势的原因,因为Dubbo缓存的Class并不会全部实例化,而是按需实例化并缓存,因此性能最好
被缓存的Class和对象实例可以根据不同的特性分为不同的类别:
- 普通包装类
最基础的,配置在SPI配置文件中的扩展类实现 - 包装扩展类
这种Wrapper类没有具体的实现,只是做了通用逻辑的抽象,并且需要在构造方法中传入一个具体的扩展接口的实现.属于Dubbo的自动包装特性. - 自适应扩展类
一个扩展接口会有多种实现类,具体使用哪个实现类可以不写死在代码或配置里,通过传入URL中的某些参数动态来确定.这属于扩展点的智适应特性. - 其他缓存
如扩展类加载器缓存,扩展名缓存等
Class缓存:
| 集合名 | 缓存类型 |
|---|---|
| Holder<Map<String, Class<?>>> cachedClasses | 普通扩展类缓存,不包括自适应扩展类和Wrapper类 |
| Set<Class<?>> cachedWrapperClasses | Wrapper类缓存 |
| Class<?> cachedAdaptiveClass | 自适应扩展类缓存 |
| ConcurrentMap<String, Holder | 扩展名与扩展对象缓存 |
| Holder | 实例化后的自适应(Adaptive)扩展对象,只能同时存在一个 |
| ConcurrentMap<Class<?>, String> cachedNames | 扩展类与扩展名缓存 |
| ConcurrentMap<Class, ExtensionLoader> EXTENSION_LOADERS | 扩展类与对应的扩展类加载器缓存 |
| ConcurrentMap<Class<?>, Object> EXTENSION_INSTANCES | 扩展类与类初始化后的实例 |
| Map<String, Active> cachedActivates | 扩展名与@Active的缓存 |
扩展点的特性
扩展类一共包含四种特性:自动包装,自动加载,自适应和自动激活
自动包装
ExtensionLoader在加载扩展时,如果发现这个扩展类包含其他扩展点作为构造函数的参数,则这个扩展类就会被认为是Wrapper类.Wrapper类示例代码:
1 | public class ProtocolFilterWrapper implements Protocol { |
ProtocolFilterWrapper虽然继承了protocol, 但是其构造函数中又注入了一个Protocol类型的参数,因此ProtocolFilterWrapper被认为是一个Wrapper类.这是一种装饰器模式,把通用的抽象逻辑进行封装或对子类进行增强,让子类更加专注具体的实现
自动加载
除了在构造函数中传入其他扩展实例,我们还经常使用setter方法设置属性值,如果某个扩展类时另外一个扩展点类的成员属性,并且拥有setter方法,那么框架也会自动注入对应的扩展点实例.ExtensionLoader在执行扩展点初始化的时候,会自动通过setter方法注入对应的实现类.
这里存在一个问题,如果扩展类属性是一个接口,它有多种实现,那么具体注入那个要通过自适应特性判断
自适应
在Dubbo SPI中,我们使用@Adaptive注解,可动态地通过URL中的参数来确定姚世勇哪个具体的实现类,从而解决自动加载中的实例注入问题.示例代码:
1 |
|
@Adaptice注解传入了两个Constants中的参数,它们的值分别是"server"和"transporter".当外部调用Transporter#bind方法时,会动态从传入的参数URL中提取key参数"server"的value,如果能匹配上某个扩展实现类则直接使用对应的实现类;如果未匹配上,则继续通过第二个key参数"transporter"提取value;如果都没匹配上则抛出异常.即,如果@Adaptive中传入了多个参数,则依次进行实现类匹配,知道最后抛出异常.
这种动态寻找实现类的方式比较灵活,但只能激活一个具体的实现类,如果需要多个实现类同时被激活,如Filter可以同时有多个过滤器;或者根据不同的条件,同时激活多个实现类,则需要依靠最后一个特性.
自动激活
使用@Active注解,可以标记对应的扩展点默认被激活启用.该注解可以传入不同的参数,设置扩展点在不同条件下自动激活.主要的使用场景是某个扩展点的多个实现类需要同时启用.
扩展点注解
扩展点注解: @SPI
@SPI注解可以使用类,接口,枚举上,Dubbo框架中都是使用在接口上的.它的主要作用就是标记这个接口是一个Dubbo SPI接口,即是一个扩展点,可以有多个不同的内置或用户定义的实现.运行时需要通过配置找到具体的实现类.@SPI注解的源码:
1 |
|
@SPI注解有一个value属性,通过这个属性我们可以传入不同的参数来设置这个接口的默认实现类.例如,我们可以看到Transporter接口使用Netty作为默认实现:
1 |
|
Dubbo中很多地方通过getExtension(Class
扩展点自适应注解: @Adaptive
@Adaptive注解可以标记在类,接口和方法上,但是在整个Dubbo框架中,只有几个地方使用在类级别上,如AdaptiveExtensionFactory和AdaptiveCompiler,其余都标注在方法上.如果标注在接口的方法上,即方法级别的注解,则可以通过参数动态获得实现类.方法级别注解在第一次getExtension时,会自动生成和编译一个动态的Adaptive类,从而达到动态实现类的效果.
例如上面的Transporter接口再bind和connect两个方法上添加了@Adaptive注解.Dubbo在初始化扩扎你按时,会生成一个Transporter$Adaptive类,里面会实现这两个方法,方法里会有一些抽象的通用逻辑,通过Adaptive传入的参数,找到并调用真正的实现类.
如Dubbo的Transporter的bind方法:
1 |
|
两种实现:

TODO:什么玩意啊以后再看
扩展点自动激活注解: @Activate
@Activate可以标记在类,接口,枚举类和方法上.主要使用在有多个扩展点实现,需要根据不同条件被激活的场景中.如Filter需要多个同时激活,因为每个Filter实现的是不同的功能.
@Activate可传入的参数:
| 参数名 | 效果 |
|---|---|
| String[] group() | URL的分组如果匹配则激活,则可以设置多个 |
| String[] value() | 查找URL中如果含有该key值,则会激活 |
| String[] before() | 填写扩展点列表,表示哪些扩展点要在本扩展点之前 |
| String[] after() | 同上,表示哪些扩展点要在本扩展点之后 |
| int order() | 直接的排序信息 |
ExtensionLoader的工作原理
ExtensionLoader是整个扩展机制的主要逻辑类,在这个类里面实现了配置的加载,扩展类缓存,自适应对象生成等所有工作.
工作流程
ExtensionLoader的逻辑入口可以分为getExtension,getAdaptiveExtension,getActivateExtension,分别是获取普通扩展类,获取自适应扩展类,获取自动激活的扩展类.
总体逻辑从调用这三个方法开始,每个方法可能有不同的重载方法.
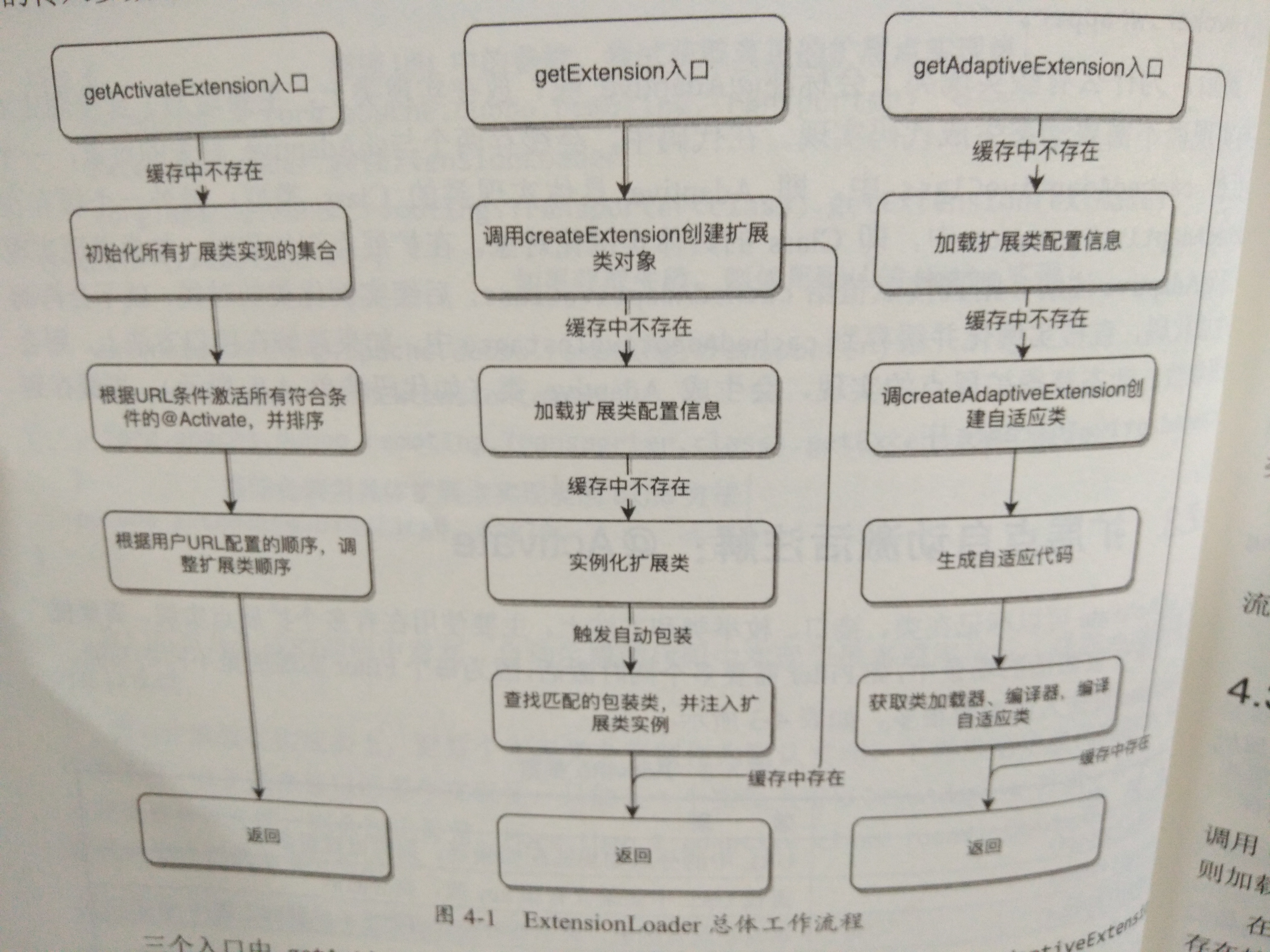
三个入口中,getActivateExtension对getExtension的依赖比较重,getAdaptiveExtension则相对独立
getActivateExtension方法只是根据不同的条件同时激活多个普通扩展类,因此,该方法中只会做一些通用的判断逻辑,如接口中是否包含@Activate注解,匹配条件是否符合等.最终还是通过调用GetExtension方法获得具体扩展点实现类.
getExtension(String name)是整个扩展加载器中最核心的方法,实现了一个完整的普通扩展类加载过程.加载过程中的每一步,都会先检查缓存中是否已经存在所需的数据,如果存在则直接从缓存中读取,没有则重新加载.这个方法每次只会根据名称返回一个扩展点实现类.
初始化过程:
- 框架读取SPI对应路径下的配置文件,并根据配置加载所有扩展类并缓存(不初始化)
- 根据传入的名称初始化对应的扩展类
- 尝试查找符合条件的包装类
- 返回对应的扩展类实例
getAdaptiveExtension也相对独立,只有加载配置信息部分与getExtension共用了同一个方法.和普通扩展类一样,框架会先检查缓存中是否有已经初始化好的Adaptive实例,没有则调用createAdaptiveExtension重新初始化.
初始化过程:
- 加载配置文件
- 生成自适应类的代码字符串
- 获取类加载器和编译器,并用编译器编译刚刚生成的代码字符.Dubbo一共有三种类型的编译器实现(后面会讲到)
- 返回对应的自适应类实例
getExtension的实现原理
当调用getExtension(String name)方法时,会先检查缓存中是否有线程的数据,没有则调用createExtension开始创建.这里有个特殊点,如果getExtension传入的name是true,则加载并返回默认扩展类.
在调用createExtension开始创建的过程中,也会先检查缓存中是否有配置信息,如果不存在扩展类,则会从resources中加载.
加载完扩展点配置后,再通过反射获得所有扩展实现类并缓存起来,这时,JVM仅仅将Class加载进内存中,但并没有做初始化.在加载Class文件时,会根据Class上的注解来判断扩展点类型,再根据类型分类做缓存.
最后,根据传入的name找到对应的类并通过Class.forName方法进行初始化,为其注入依赖的其他扩展类(自动加载特性).当扩展类初始化后,会检查一次包装扩展类Set<Class<?>>wrapperClasses,查找包含与扩展点类型相同的构造函数,为其注入刚初始化的扩展类.依赖注入代码:
1 | injectExtension(instance); // 向扩展类注入其他依赖属性,如扩展类A又依赖的扩展类B |
在injectExtension方法中可以为类注入依赖属性,它使用了ExtensionFactory#getExtension(Class
injectionExtension方法总体实现了类似Spring的IoC机制,其实现原理比较简单:首先通过反射获取类的所有方法,然后遍历以字符串set开头的方法,得到set方法参数类型,再通过ExtensionFactory寻找参数类型相同的扩展类实例,如果找到,就设值进去.
1 | for (Method method : instance.getClass().getMethods()) { |
从上面代码可知包装类的构造参数注入也是通过injectionExtension方法实现的
getAdaptiveExtension的实现原理
TODO
扩展点动态编译的实现
动态编译时Dubbo SPI自适应特性的基础,因为动态生成的自适应类只是字符串,需要通过编译得到真正的Class.虽然可以使用反射来动态代理一个类,但是在性能上和直接编译好的Class会有一定差距.Dubbo SPI通过代理的动态生成,配合动态编译器,灵活地在原始类的基础上创建新的自适应类.
总体结构
Dubbo中有三种代码编译器,分别是JDK编译器,Javassist编译器和AdaptiveCompiler编译器.这几种编译器都实现了Compiler接口.
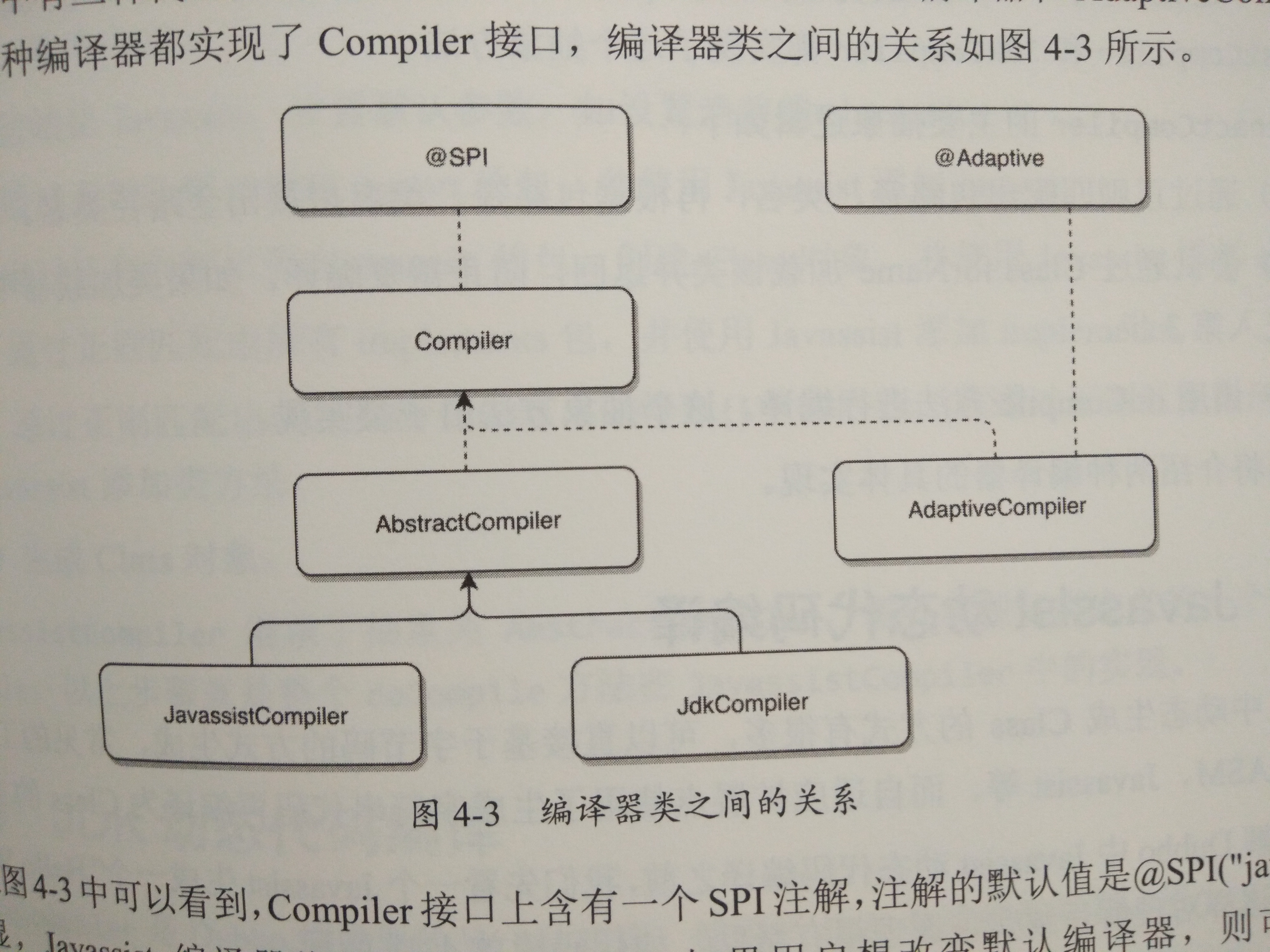
Compile接口上含有一个SPI注解,注解的默认值是@SPI(“javassist”)
AdaptiveCompiler上面有@Adaptive注解,说明AdaptiveCompiler会固定为默认实现,这个Compiler的主要作用和AdaptiveExtensionFactory相似,就是为了管理其他Compiler.
AdaptiveCompiler#setDefaultCompiler方法会在ApplicationConfig中被调用,也就是Dubbo在启动时,会解析配置中的<dubbo:application compiler=“jdk” />标签,获取设置的值,初始化对应的编译器.
AbstractCompiler是一个抽象类,里面封装了通用的模板逻辑.还定义了一个抽象方法doCompile,留给子类来实现具体的编译逻辑.AbstractCompiler的主要抽象逻辑如下:
- 通过正则匹配出包路径,类名,再根据包路径,类名拼接出全路径名
- 尝试通过Class.forName加载类并返回,防止重复编译.如果类加载器中没有这个类,则进入第三步
- 调用doCompile方法进行编译
Javassist动态代码编译
Java中动态生成Class的方式有很多,可以直接基于字节码的方式生成,常见的工具有CGLIB,ASM,Javassist等.而自适应扩展点使用了生成字符串代码再编译为Class的方式.
Javassist生成一个"Hello World"的例子:
1 | ClassPool classPool = ClassPool.getDefault(); |
Javassist不断通过正则表达式匹配不同不问的代码,然后调用Javassist库中的API生成不同部位的代码,最后得到一个CLass对象:
- 初始化Javassist,设置默认参数,如设置当前的classpath
- 通过正则匹配出所有import包,并使用Javassist添加import
- 通过正则匹配出所有的extends包,创建Class对象,并使用Javassist添加extends
- 通过正则匹配出所有implements包,并使用Javassist添加implements
- 通过正则匹配出类里面的所有内容,即得到{}中的内容,再通过正则匹配出所有方法,并使用Javassist添加类方法
- 生成Class对象
JDK动态代码编译
JdkCompiler是Dubbo编译器的另一种实现,使用了JDK自带的编译器,原生JDK编译包位于javax.tools下,主要使用了三个东西:JavaFileObject接口,ForwardingJavaFileManager接口,JavaCompiler.CompilationTask方法.整个动态编译过程可以简单地总结为:首先初始化一个JavaFileObject对象,并把代码字符串作为参数传入构造方法,然后调用JavaCompiler.CompilationTask方法编译出具体的类.JavaFileManager负责管理类文件的输入/输出位置.
JavaFileObject接口
字符串代码会被包装成一个文件对象,并提供获取二进制流的接口.Dubbo框架中的JavaFileObjectImpl类可以看做该接口的一种扩展实现,构造方法中需要传入生成好的字符串代码,此文件对象的输入和输出都是ByteArray流.
JavaFileManager接口
主要管理文件的读取和输出位置.JDK中没有可以直接使用的实现类,唯一的实现类ForwardingJavaFileManager构造器又是protect类型,因此Dubbo中定制化实现了一个JavaFileManagerImpl类,并通过一个自定义类加载器ClassLoaderImpl完成资源加载
JavaCompiler.CompilationTask
把JavaFileObject对象编译成具体的类